Gradient boosting is an Ensemble Learning algorithm that combines several weak models, typically decision trees, to create a more accurate and robust model.
How it works
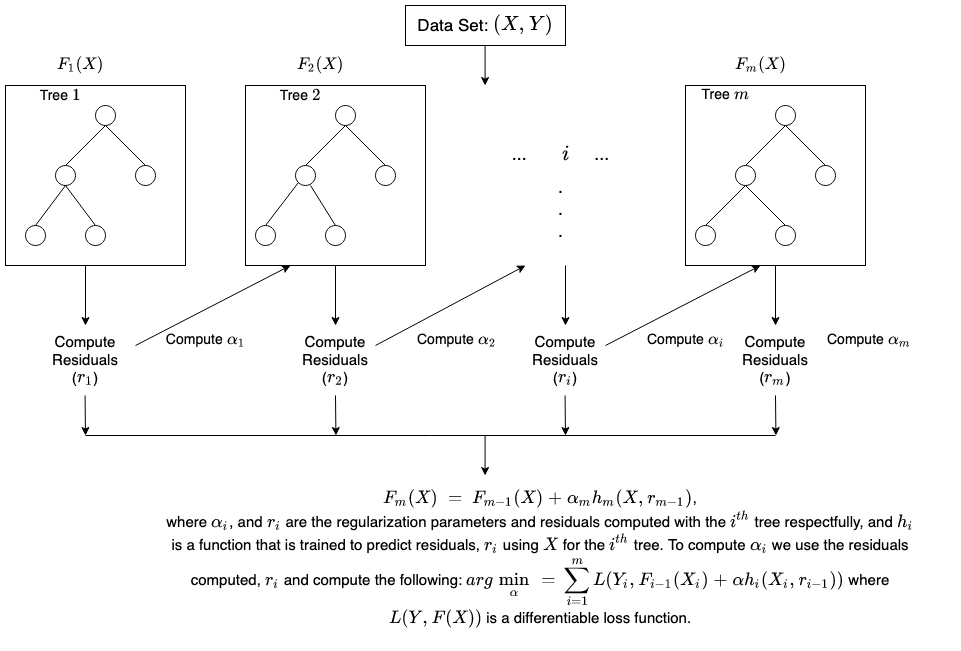
Initialize the model with a simple model or a constant value that best fits the data.
Train a weak model, such as a decision tree, on the training data.
Use the weak model to make predictions on the training data.
Compute the residuals, or the difference between the predicted values and the actual values, for each training example.
Train another weak model on the residuals from the previous model.
Combine the predictions from the previous weak model and the new weak model to get an updated prediction.
Repeat steps 4 to 6 until a stopping criteria is met, such as a maximum number of iterations or a minimum improvement in the loss function.
Use the final model to make predictions on new data.
Why it is called "gradient boosting"?
because it uses a gradient descent procedure to minimize the loss when adding new learners to the ensemble.
The key idea behind gradient boosting is that each new weak model is trained to fit the residuals of the previous model, which allows the model to focus on the most challenging examples.
XGBoost is a more regularized form of Gradient Boosting. XGBoost uses advanced Regularization (L1 & L2), which improves model generalization capabilities.
Efficient handling of missing sata
Built-in cross-validation capability (at each iteration)
System optimization
XGBoost delivers high performance as compared to normal Gradient Boosting. Its training is very fast and can be parallelized across clusters.